
Developers are migrating from on-premises technology and embracing the benefits cloud infrastructure offers. Moreso, there is a rapid shift from a monolithic architecture to microservices architecture; this ensures that apps have higher availability, are simple to install, and easy to upgrade with the microservices architecture approach. In this post, we introduced Kubernetes to front-end engineers and explained why Kubernetes is integral in a production-ready microservice architecture. Some key terms that are important for team collaboration were discussed and concluded the post with a quick deployment to getting started as a beginner.
Kubernetes, also known as k8s, was coined by a Google engineer in mid-2014 and is now widely used throughout the developer ecosystem. According to the Kuberenetes Documentation:
“Kubernetes is an open-source platform for managing containerized workloads and services that allow declarative configuration and automation. It enables developers to build containerized applications that can react to critical application needs in the event of a traffic spike or a service failure.”
Dockers and Containers
Docker is the most popular container technology tool. It is a tool used for building, running, and deploying containerized applications. An application’s code, libraries, tools, dependencies, and other files are all contained in a Docker image; when a user executes an image, it turns into a container. An image built will always only run one container (an image can have multiple layers and then be used to build multiple images, but an image will always only create one container).
Docker images can be likened to a template of instructions to build a container. It helps to abstract application code from the underlying infrastructure, simplifying version management and enabling portability across various deployment environments.
Basically, a containerized application is stateless, i.e. it does not retain session information. And since multiple instances of a container image can run simultaneously, developers use containers as instances that can be initiated to replace failed ones without disruption to the application’s operation.
In terms of resource management, it is very important to know that the use of resources is highly constrained, unlike VMs, as its access to physical resources (memory, storage, and CPU) is limited by the host OS. As a result, containers are lighter and more scalable than virtual machines.
“Containers are the foundation of modern application design and development, which means it will be almost impossible for any IT organization to avoid a container commitment.”
— Tom Nolle, “Explore Container Deployment Benefits And Core Components”
For a container deployment, there is the server for Container hosting with OS support together with a container management tool like Docker or ContainerD. When there is a need for application capabilities, such as the ability to scale under load and recover from hardware failures without disruption or human intervention, then an orchestration tool would be needed.
Kubernetes(K8s) is a container orchestration tool that takes over tasks that would otherwise require manual intervention, preventing lots of time-consuming routine checks, changes in configuration, updates, and other software maintenance work. Using Kubernetes deployment would significantly help to automate such repetitive processes and makes loads of manual jobs a breeze when working on a production-ready application.
Why Would A Front-end Developer Use Kubernetes?
For an improved digital experience, Microservices have been successfully implemented by tech giants, such as Netflix, Google, Amazon, and other industry leaders; businesses see this architecture as a cost-effective means of expanding their operations. On the other hand, microservice architecture has gained popularity in recent years due to its effectiveness in developing, deploying, and scaling multiple application backends.
Adoption of the Microservice architecture in production would be generally considered good practice when an application is simply getting too large for any single developer to fully maintain, or there is an increase in orchestration and interaction between services after every release. It is important to know that not all levels of business organization would be required to use microservices to benefit from using Kubernetes.
K8s Or Docker Compose: Which One Should I Use?
Docker-compose is a tool that accepts a YAML file that specifies a cross container application and automates the creation and removal of all those containers without the need to write several docker commands for each one. It should be used for testing and development.
Kubernetes, on the other hand, is a platform for managing production-ready containerized workloads and services that allows for declarative setup as well as automation.
Getting Familiar With Terminology
To utilize Kubernetes efficiently, one must have a reasonable understanding of its terminologies. Here are a few key terminologies to get you started:
- Docker
A container resource referring to a Docker image and provides all of the necessary configurations that Kubernetes needs (deploy, execute, expose, monitor, and safeguard the Docker container). - Container
The fundamental concept is the Container — since Kubernetes is a container orchestration tool. A container is a standard unit of software that packages up code and all that the application depends on to run reliably. - Pods
A pod is a collection of one or more containers with common storage and network resources, as well as a set of rules for how the containers should be run. It is the smallest deployable unit that Kubernetes allows you to create and manage. - Nodes
The components (physical computers or virtual machines) that run these applications are known as worker nodes. Worker nodes carry out the tasks that the master node has assigned to them. - Cluster
A cluster is a collection of nodes that are used to run containerized applications. A Kubernetes cluster is made up of a set of master nodes and a number of worker nodes. Minikube is highly suggested for new users who want to start building a Kubernetes cluster. - Objects
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses objects to represent the state of our cluster. They describe the desired state for running applications, the available resources for the running applications, and the policies guiding these applications. It holds information about cluster workload. - Namespaces
Namespaces are a way to distribute cluster resources needed for use in situations with various teams or projects with a large number of users. - Ingress Controller
Kubernetes Ingress is an API object that manages external users’ access to services in a Kubernetes cluster by providing routing rules. This external request is frequently made using HTTPS/HTTP. You can easily set up rules for traffic routing with Ingress without having to create a bunch of Load Balancers or expose each service on the node.
“Enterprises are drifting further away from monoliths and closer toward a microservice architecture for every app, website, and digital experience they develop.”
— Kaya Ismail (2018)
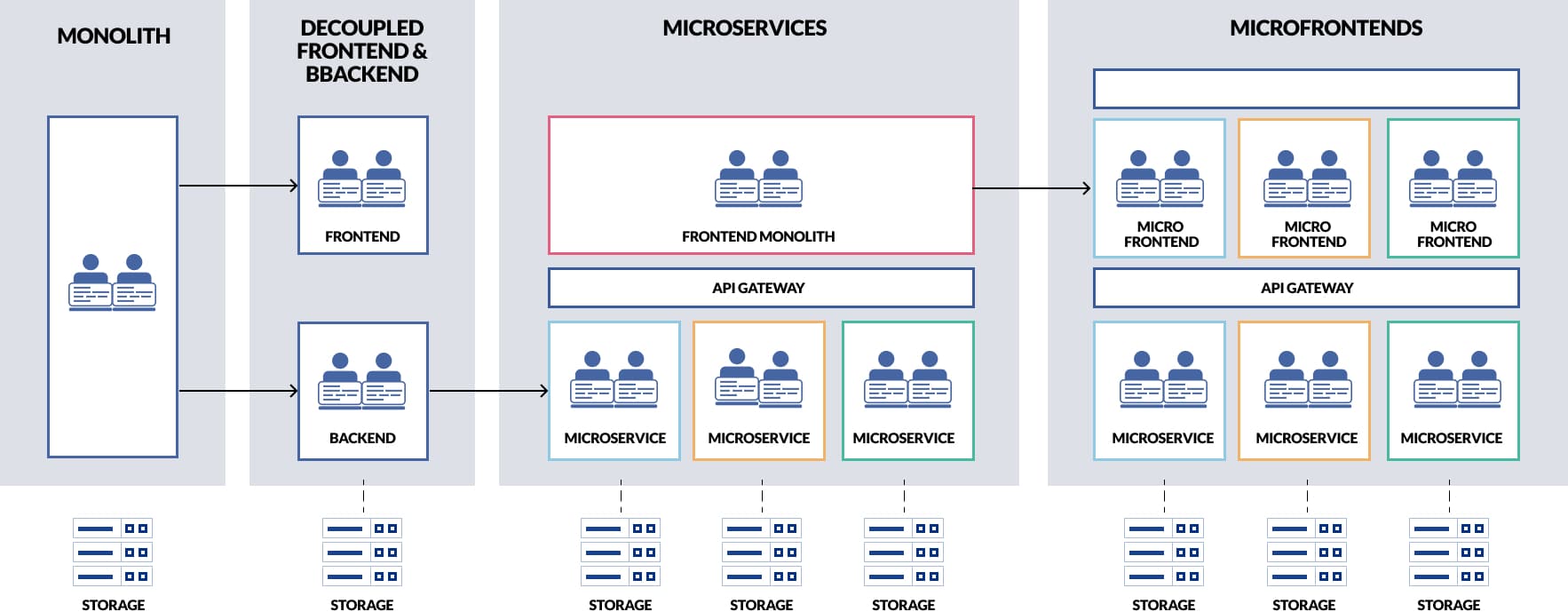
Monolithic architecture is a common way of building an infrastructure as a single unit that includes a user interface, a server-side framework, and a relational database. Since all of the app’s layers and components are interconnected, changing one component would require you to update the entire app.
Another approach is the Microservice architecture. By using the microservices approach, a complex program is broken down into loosely linked parts. Loose coupling establishes a system in which each service or component has its own logically distinct lifecycle, protocols, and database. This standalone component can be designed, implemented, scaled, and managed separately from the rest of the app which will continue to function normally.

We begin to wonder how this can interact, as we consider the two methods. This is where containerization comes in: each stand-alone unit is packed into a container which is then enclosed in a pod (which contains multiple containers that are shared in a cluster of nodes). When a Pod contains several containers, they are handled as a single entity, and all containers in the Pod share the Pod’s resources, including namespace, IP address, and network ports at the same time.

(K8s) is a container-centric infrastructure manager. It manages container lifecycles, that is to say, it optimizes container orchestration deployment by provisioning Pods (creating and destroying them) based on the application’s requirements. Kubernetes exposes pods to requests using the Service object which maps IP addresses to a collection of pods. The service ensures routes to the Pods from any authorized source (within or outside the cluster) through a designated port.
As for front-end developers, we do need to have basic knowledge of setting up the inter-communication between this infrastructure and services. A clear understanding of how things function is essential.
Often referred to as an Ops problem and that by giving it up, we are missing out on opportunities to understand the possibilities of what we create and how we can improve its availability in production.
While the Ops role should be in charge of cluster setup, configuration, and management, the developer should be aware of and responsible for putting up the bare minimum necessary to run their app.
As a result, understanding the fundamentals of Kubernetes will allow you to optimize the configuration of your application and make it more scalable; and such to participate in the release process of what they created.
Teams would benefit from having a general understanding of Kubernetes around the software stack while sharing terminologies and addressing their project. It also allows you complete control over the entire project lifecycle — from code to implementation — allowing you to test the application’s deployment, understand how your project should be deployed, and assist in maintaining the layer as well as specifying the environment.
A good example is when a friend Cari (software engineer) described her experience working with a team a few years ago, where the -end engineers were only interested in getting involved in front-end development and Kubernetes alone. They willingly chose to learn Kubernetes and wouldn’t want to directly work with the backend layers, but only consume it. The team enjoyed having the ability to define how their application is deployed on Kubernetes.
Having this control over their project helps them be a part of the release journey of their projects, and more importantly will allow you to optimize the configuration of your application and make it more scalable. Also, understanding the production-deployment configuration allows developers to spot and fix crucial micro performance issues such as caching, amount of requests, and time-to-first-byte, as well as knowing how staging/testing differs from production before releasing the app.
There are scenarios where the terminology often overlaps between front-end and back-end teams, for example:
- port and services
When specifying a version of an app deployed, and then the ports exposed e.g. “we can interact with our application using the service name and port xx: xx”. - namespaces
Knowing that our project sits in a namespace on Kubernetes. Namespaces are a way for multiple users to share cluster resources. - RBAC (Role-Based Access and Control)
Knowing how the access control permissions on Kubernetes affect your projects.
An understanding of how Docker images build and run will allow teams to clearly communicate the requirements for each application in the cluster.
Deployment and service
The resources that you identified in a configuration are created by a deployment. All of the resources that make up a deployment are specified in a configuration file.
To make a deployment, you’ll need a configuration file. YAML syntax is required for a configuration file. It contains fields, such as version, name, kind, replicas field (the desired number of Pod resources), selector, and the label field, etc, as shown below:
.... name: spec: selector: matchLabels: app: tier: replicas: metadata: labels: app: tier: spec: containers: - name: image: ...A Kubernetes Service, on the other hand, is an abstraction layer that describes a logical group of Pods and allows for external traffic exposure, load balancing, and service discovery for such Pods.
Updating a Deployment
A deployment can be updated to the desired object state from the current state, this is often done declaratively by updating the objects of interest in the configuration file and then deploying as an update. With a rolling update deployment strategy, old Pod resources will be gradually replaced with new ones. This means that two Pod resource versions can be deployed and accessed at the same time while ensuring that there is no downtime.

Backend Service Object
In this article, the Pods in the front-end Deployment will run an Nginx image that will be configured to proxy requests to a Service with the key of app: backend. We assume the backend team has already ensured that their pods are running on the cluster, and that we only want to create and connect our app via a deployment to the backend.
In order to allow access to the backend application, we need to create a service for it. A Service creates a persistent IP address and DNS name entry for the application in question which makes it accessible to other pods. It also uses selectors to find the Pods that it routes traffic to.
Here is an example of a backend-service.yaml configuration file which would expose the backend app to other pods in the cluster. Below is the sample backend service configuration file:
---
apiVersion: v1
kind: Service
metadata: name: backend-serv
spec: selector: app: hello tier: backend ports: - protocol: TCP port: 80 ...The above YAML file shows that the service is configured to route traffic to the Pods that have the label app: hello and tier: backend of the cluster through port 80 only.
Creating the Frontend
You typically create a container image of your application and push it to a registry (e.g. docker registry) before referring to it in a Pod. Since this is an introductory article, we will make use of a sample front-end image from the google container repository. The frontend sends requests to the backend worker Pods by using the DNS name given to the backend Service which is the value of the name field in the backend-service.yaml configuration file.
The Pods in the front-end Deployment run an Nginx image that is configured to proxy requests to the backend Service. The configuration file specifies the server and the listening port. When an ingress is created in Kubernetes, nginx upstreams point to services that match specified selectors.
nginx.conf configuration file
upstream Backend { server backend-serv;
}
server { listen 80; location / { proxy_pass http://Backend; }
}
Note that the internal DNS name used by the backend Service inside Kubernetes is used to specify.
The frontend, like the backend, has a Deployment and a Service. The setup for the front-end Service has type: LoadBalancer which means that the Service would use a load balancer provisioned by the cloud service provider and would be reachable from outside the cluster.
---
apiVersion: v1
kind: Service
metadata: name: frontend-serv
spec: selector: app: hello tier: frontend ports: - protocol: "TCP" port: 80 targetPort: 80 type: LoadBalancer
...---
apiVersion: apps/v1
kind: Deployment
metadata: name: frontend-depl
spec: selector: matchLabels: app: hello tier: frontend track: stable replicas: 1 template: metadata: labels: app: hello tier: frontend track: stable spec: containers: - name: nginx image: "gcr.io/google-samples/hello-frontend:1.0" ...Create The Front-End Deployment And Service
Now, that the configuration files are ready, we can run a kubectl apply command to create the resources as specified:
kubectl apply -f [insert URL to saved frontend-deployment YAML file] kubectl apply -f [insert URL to saved frontend-service YAML file]The output verifies that both resources were created:
deployment.apps/frontend-depl created
service/frontend-serv createdInteracting with the Front-end Deployment and Service
You can use this command to obtain the external IP address, once you’ve created a LoadBalancer Service:
kubectl get service frontend-serv –watch
This shows the front-end Service’s configurations and monitors for changes. The internal cluster IP would be immediately provisioned, while the external IP address is initially marked as pending:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend-serv LoadBalancer 10.xx.xxx.xxx <pending> 80/TCP 10sAs soon as an external IP is provisioned, however, the configuration updates to include the new IP under theEXTERNAL-IPheading:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend-serv LoadBalancer 10.xx.xxx.xx XXX.XXX.XXX.XXX 80/TCP 1mThe provisioned IP can be used to communicate with the front-end service from outside the cluster. We can now send traffic through the frontend, because the frontend and backend are now linked. Using the curl command on the external IP of your front-end Service, we can reach the endpoint.
Conclusion
A company-wide vision for providing reliable software may be driven by a broad understanding of Kubernetes and how your application works on Kubernetes. The microservices architecture is more beneficial for complex and evolving applications. It offers effective solutions for handling a complicated system of different functions and services within one application.
However, it is critical to understand that the microservice design is not appropriate for every level of business organization. You should start with a monolith if your business idea is new and you want to validate it. For a small technical team attempting to design a basic and lightweight application, microservices can be considered superfluous, since monolith can be deployed via Kube without any problems, and you can still benefit from replication options and other features.
Further Reading On Smashing Magazine
(yk, nl, il)