
GraphQL enables an API developer to model application data as a graph, and API clients that request that data to easily traverse this data graph to retrieve it. These are powerful game-changing capabilities. But if your backend isn’t graph-ready, these capabilities could become liabilities by putting additional pressure on your database, consuming greater time and resources.
In this article, I’ll shed some light on ways you can mitigate these issues when you use a graph database as the backend for your next GraphQL API by taking advantage of the capabilities offered by the open-source Neo4j GraphQL Library.
What Graphs Are, And Why They Need A Database
Fundamentally, a graph is a data structure composed of nodes (the entities in the data model) along with the relationships between nodes. Graphs are all about the connections in your data. For this reason, relationships are first-class citizens in the graph data model.
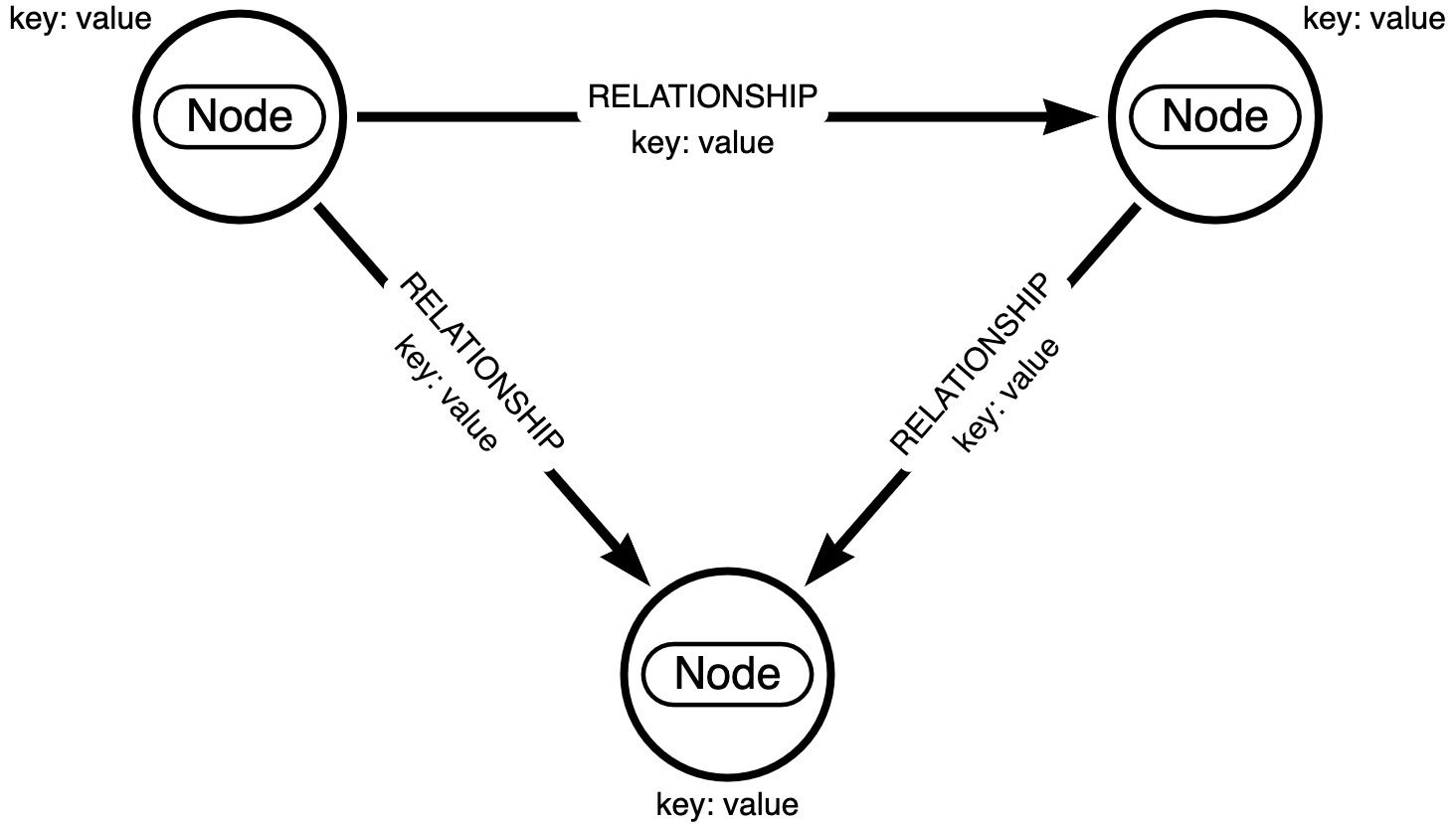
Graphs are so important that an entire category of databases was created to work with graphs: graph databases. Unlike relational or document databases that use tables or documents, respectively, as their data models, the data model of a graph database is (you guessed it!) a graph.

GraphQL is not and was never intended to be a database query language. It is indeed a query language, yet it lacks much of the semantics we would expect from a true database query language like SQL or Cypher. That’s on purpose. You don’t want to be exposing our entire database to all our client applications out there in the world.
Instead, GraphQL is an API query language, modeling application data as a graph and purpose-built for exposing and querying that data graph, just as SQL and Cypher were purpose-built for working with relational and graph databases, respectively. Since one of the primary functions of an API application is to interact with a database, it makes sense that GraphQL database integrations should help build GraphQL APIs that are backed by a database. That’s exactly what the Neo4j GraphQL Library does — makes it easier to build GraphQL APIs backed by Neo4j.
One of GraphQL’s most powerful capabilities enables the API designer to express the entire data domain as a graph using nodes and relationships. This way, API clients can traverse the data graph to find the relevant data. This makes better sense because most API interactions are done in the context of relationships. For example, if we want to fetch all orders placed by a specific customer or all the products in a given order, we’re traversing the pattern of relationships to find those connections in our data.
Soon after GraphQL was open-sourced by Facebook in 2015, a crop of GraphQL database integrations sprung up, evidently in an effort to address the n+1 conundrum and similar problems. Neo4j GraphQL Library was one of these integrations.

Common GraphQL Implementation Problems
Building a GraphQL API service requires you to perform two steps:
- Define the schema and type definitions.
- Create resolver functions for each type and field in the schema that will be responsible for fetching or updating data in our data layer.
Combining these schema and resolver functions gives you an executable GraphQL schema object. You may then attach the schema object to a networking layer, such as a Node.js web server or lambda function, to expose the GraphQL API to clients. Often developers will use tools like Apollo Server or GraphQL Yoga to help with this process, but it’s still up to them to handle the first two steps.
If you’ve ever written resolver functions, you’ll recall they can be a bit tedious, as they’re typically filled with boilerplate data fetching code. But even worse than lost developer productivity is the dreaded n+1 query problem. Because of the nested way that GraphQL resolver functions are called, a single GraphQL request can result in multiple round-trip requests to the database. Addressing this typically involves a batching and caching strategy, adding additional complexity to your GraphQL application.
Doubling Down On GraphQL-First Development
Originally, the term GraphQL-First Development described a collaborative process. Frontend and backend teams would agree on a GraphQL schema, then go to work independently building their respective pieces of the codebase. Database integrations extend the idea of GraphQL-First development by applying this concept to the database as well. GraphQL-type definitions can now drive the database.
You can find the full code examples presented here on GitHub.
Let’s say you’re building a business reviews application where you want to keep track of businesses, users, and user reviews. GraphQL-type definitions to describe this API might look something like this:
type Business { businessId: ID! name: String! city: String! state: String! address: String! location: Point! reviews: [Review!]! @relationship(type: "REVIEWS", direction: IN) categories: [Category!]! @relationship(type: "IN_CATEGORY", direction: OUT)
} type User { userID: ID! name: String! reviews: [Review!]! @relationship(type: "WROTE", direction: OUT)
} type Review { reviewId: ID! stars: Float! date: Date! text: String user: User! @relationship(type: "WROTE", direction: IN) business: Business! @relationship(type: "REVIEWS", direction: OUT)
} type Category { name: String! businesses: [Business!]! @relationship(type: "IN_CATEGORY", direction: IN)
}
Note the use of the GraphQL schema directive @relationship in our type definitions. GraphQL schema directives are the language’s built-in extension mechanism and key components for extending and configuring GraphQL APIs — especially with database integrations like Neo4j GraphQL Library. In this case, the @relationship directive encodes the relationship type and direction (in or out) for pairs of nodes in the database.
Type definitions are then used to define the property graph data model in Neo4j. Instead of maintaining two schemas (one for our database and another for our API), you can now use type definitions to define both the API and the database’s data model. Furthermore, since Neo4j is schema-optional, using GraphQL to drive the database adds a layer of type safety to your application.

From GraphQL Type Definitions To Complete API Schemas
In GraphQL, you use fields on special types (Query, Mutation, and Subscription) to define the entry points for the API. In addition, you may want to define field arguments that can be passed at query time, for example, for sorting or filtering. Neo4j GraphQL Library handles this by creating entry points in the GraphQL API for create, read, update, and delete operations for each type, as well as field arguments for sorting and filtering.
Let’s look at some examples. For our business reviews application, suppose you want to show a list of businesses sorted alphabetically by name. Neo4j GraphQL Library automatically adds field arguments to accomplish just this.
{ businesses(options: { limit: 10, sort: { name: ASC } }) { name }
}
Perhaps you want to allow the users to filter this list of businesses by searching for companies by name or keyword. The where argument handles this kind of filtering:
{ businesses(where: { name_CONTAINS: "Brew" }) { name address }
You can then combine these filter arguments to express very complex operations. Say you want to find businesses that are in either the Coffee or Breakfast category and filter for reviews containing the keyword “breakfast sandwich:”
{ businesses( where: { OR: [ { categories_SOME: { name: "Coffee" } } { categories_SOME: { name: "Breakfast" } } ] } ) { name address reviews(where: { text_CONTAINS: "breakfast sandwich" }) { stars text } }
}
Using location data, for example, you can even search for businesses within 1 km of our current location:
{ businesses( where: { location_LT: { distance: 1000 point: { latitude: 37.563675, longitude: -122.322243 } } } ) { name address city state }
}
As you can see, this functionality is extremely powerful, and the generated API can be configured through the use of GraphQL schema directives.
We Don’t Need No Stinking Resolvers
As we noted earlier, GraphQL server implementations require resolver functions where the logic for interacting with the data layer lives. With database integrations such as Neo4j GraphQL Library, resolvers are generated for you at query time for translating arbitrary GraphQL requests into singular, encapsulated database queries. This is a huge developer productivity win (we don’t have to write boilerplate data fetching code — yay!). It also addresses the n+1 query problem by making a single round-trip request to the database.
Moreover, graph databases like Neo4j are optimized for exactly the kind of nested graph data traversals commonly expressed in GraphQL. Let’s see this in action. Once you’ve defined your GraphQL type definitions, here’s all the code necessary to spin up your fully functional GraphQL API:
const { ApolloServer } = require("apollo-server");
const neo4j = require("neo4j-driver");
const { Neo4jGraphQL } = require("@neo4j/graphql"); // Connect to your Neo4j instance.
const driver = neo4j.driver( "neo4j+s://my-neo4j-db.com", neo4j.auth.basic("neo4j", "letmein")
); // Pass our GraphQL type definitions and Neo4j driver instance.
const neoSchema = new Neo4jGraphQL({ typeDefs, driver }); // Generate an executable GraphQL schema object and start
// Apollo Server.
neoSchema.getSchema().then((schema) => { const server = new ApolloServer({ schema, }); server.listen().then(({ url }) => { console.log(`GraphQL server ready at ${url}`); });
});
That’s it! No resolvers.
Extend GraphQL With The Power Of Cypher
So far, we’ve only been talking about basic create, read, update, and delete operations. How can you handle custom logic with Neo4j GraphQL Library?
Let’s say you want to show recommended businesses to your users based on their search or review history. One way would be to implement your own resolver function with the logic for generating those personalized recommendations built in. Yet there’s a better way to maintain the one-to-one, GraphQL-to-database operation performance guarantee: You can leverage the power of the Cypher query language using the @cypher GraphQL schema directive to define your custom logic within your GraphQL type definitions.
Cypher is an extremely powerful language that enables you to express complex graph patterns using ASCII-art-like declarative syntax. I won’t go into detail about Cypher in this article, but let’s see how you could accomplish our personalized recommendation task by adding a new field to your GraphQL-type definitions:
extend type Business { recommended(first: Int = 1): [Business!]! @cypher( statement: """ MATCH (this)<-[:REVIEWS]-(:Review)<-[:WROTE]-(u:User) MATCH (u)-[:WROTE]->(:Review)-[:REVIEWS]->(rec:Business) WITH rec, COUNT(*) AS score RETURN rec ORDER BY score DESC LIMIT $first """ )
}
Here, the Business type has a recommended field, which uses the Cypher query defined above to show recommended businesses whenever requested in the GraphQL query. You didn’t need to write a custom resolver to accomplish this. Neo4j GraphQL Library is still able to generate a single database request even when using a custom recommended field.
GraphQL Database Integrations Under The Hood
GraphQL database integrations like Neo4j GraphQL Library are powered by the GraphQLResolveInfo object. This object is passed to all resolvers, including the ones generated for us by Neo4j GraphQL Library. It contains information about both the GraphQL schema and GraphQL operation being resolved. By closely inspecting this object, GraphQL database integrations can generate database queries at the time queries are placed.

If you’re interested, I recently gave a talk at GraphQL Summit that goes into much more detail.
An open-source library that works with any JavaScript GraphQL implementation can conceivably power an entire ecosystem of low-code GraphQL tools. Collectively, these tools leverage the functionality of Neo4j GraphQL Library to help make it easier for you to build, test, and deploy GraphQL APIs backed by a real graph database.
For example, GraphQL Mesh uses Neo4j GraphQL Library to enable Neo4j as a data source for data federation. Don’t want to write the code necessary to build a GraphQL API for testing and development? The Neo4j GraphQL Toolbox is an open-source, low-code web UI that wraps Neo4j GraphQL Library. This way, it can generate a GraphQL API from an existing Neo4j database with a single click.

Where From Here
If building a GraphQL API backed by a native graph database sounds interesting or at all helpful for the problems you’re trying to solve as a developer, I would encourage you to give the Neo4j GraphQL Library a try. Also, the Neo4j GraphQL Library landing page is a good starting point for documentation, further examples, and comprehensive workshops.
I’ve also written a book Full Stack GraphQL Applications, published by Manning, that covers this topic in much more depth. My book covers handling authorization, working with the frontend application, and using cloud services like Auth0, Netlify, AWS Lambda, and Neo4j Aura to deploy a full-stack GraphQL application. In fact, I’ve built out the very business reviews application from this article as an example in the book! Thanks to Neo4j, this book is now available as a free download.
Last but not least, I will be presenting a live session entitled “Making Sense of Geospatial Data with Knowledge Graphs” during the NODES 2022 virtual conference on Wednesday, November 16, produced by Neo4j. Registration is free to all attendees.
(yk, il)