
When deploying websites, there’s rarely a one-size-fits-all solution. Some websites benefit from server-rendered pages, some prefer statically generating content upfront. In this article, Stefan explains how a CMS such as Storyblok can help you make your site more resilient without losing the flexibility to deliver time-relevant content.
In the last couple of years, our industry has figured out how to make use of cloud infrastructure and flexible deployments in the best way possible. We use services that give us continuous integration without headaches and serve static files without us managing anything. And adding the right framework to the mix, those services blur the line between static files, dynamic updates, and serverless APIs.
In all of this, one fundamental piece is often left out: storing data. This raises the question, “Where does our content come from?” Well, a headless content management system might just be what you need.
The Mighty Monolith And Opinions
In order to understand why we get so many benefits out of architectures that involve headless systems, we need to understand how things worked with a more traditional approach: monolithic architectures.
Not so long ago, monolithic content management systems were the jack-of-all-trades for your web content delivery concerns. They came along with:
- a database (or required a very specific one),
- the logic to read, change, and store data,
- user interfaces for content administration,
- logic to render all your content in deliverable formats such as HTML or JSON,
- the ability to upload, store, and deliver assets like images and static files,
- sometimes even an editor for design,
- a routing logic to map readable URLs to actual data in your system.
That’s a lot of tasks! Furthermore, a monolithic CMS more often than not was very opinionated in its choice of tools and flavors. For example, if you were lucky, you got a template engine to define the markup you wanted to produce and had absolute control over it. It might not have been as featureful as you wanted it to be, but it at least was better than mixing PHP code with HTML tags.
Being this opinionated left you as a developer with two choices:
- Submit to the system.
Learn all its intricacies inside out, become an expert, and don’t deviate from the standard. Treat a CMS as a framework with all the benefits and downsides that come with them. Be super productive if you follow the rules. Avoid anything that doesn’t play well with the opinions of your tool of choice. This can go well for a long time. But you become very inflexible if there are changes in requirements. Not only if you need a different front-end to deploy that is to be designed differently than your tool allows, but also if you end up needing to scale out your servers because of increased traffic, or you need to establish stricter security because of new attack vectors you can’t mitigate. Don’t get me wrong, people who produce and develop monolithic CMS know about those challenges and work on them. It’s still not your choice if you want change. - Work around the system.
This is arguably worse than following a framework blindly. If you work around a system, try to integrate functionality via plug-ins, shift responsibility to attached systems on the side, try to hack something in the core to get things done your way (yes, this happens as well), you end up frankensteining your solution until it’s unrecognizable anymore. While this gives you flexibility when your product managers want to crank out features, it will fall back on you sometime in the future. Don’t do this.
None of these choices is something we want to have. And it all happens because we mix responsibilities in one single solution: How we define, maintain, and store content is mixed with the creation of views.
The following chart shows what happens if we want to see content produced by a traditional, server-side rendered system.
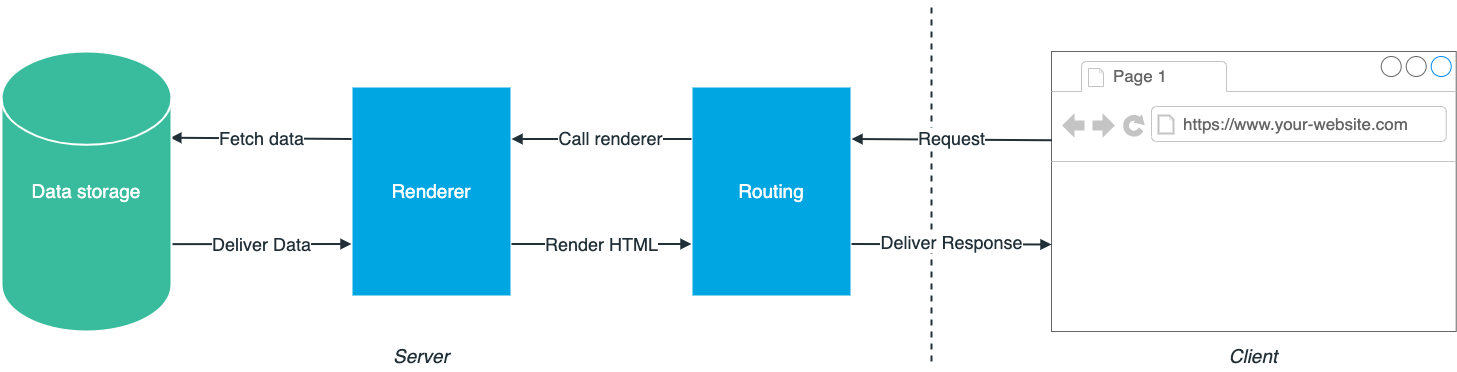
- A client, maybe a browser, requests a website from a server via a URL;
- A router resolves the URL and maps it to some input parameters that the system can understand;
- It asks a rendering component to render content based on said input parameters;
- Then, in return, it needs to ask the data storage if this content is available;
- One pierce through the layer cake, and you get your content back;
- The renderer renders it into HTML;
- The routing layer can send a response to the client.
Every communication between the components of this layered architecture is subject to the opinions of its creator. In monolithic architectures, these are the content management system’s opinions. If you want to change them, you have to go the extra mile.
The Promise Of Headless Architectures
And this is exactly where headless content management systems come in. A headless CMS gives you easy reading access to the data. Everything else can be designed according to your opinions.
You decide how to resolve routing. On the client? On a web proxy? In a Node.js server? Your choice. You decide how and where to render content. Again, on the client? With blade templates in PHP on the server? A serverless function on AWS Lambda written in Go that spits out JSON? Your choice.

Chopping of the head gives you as a developer the freedom to decide what is the right technology for your situation. From a single page application to a traditional server-side rendered website or pre-built sites in continuous integration.
Suddenly you also get the freedom to update “the head” as many times as you like and as often as you need. You can deploy it to different servers with different scaling possibilities. Remix, Nuxt, Laravel, 11ty… They couldn’t be more different in how they work, and how they’re supposed to be deployed. Your CMS stays the same.
An unknown error in your render logic might cause the same kind of problems as if your database has no room to write anymore. By attaching a headless content management system moves a potential source of problems away from others. Suddenly, the boundary becomes clearer — and we can even go further.
What if we cannot only define the error boundary much better? What if we can react to potential errors much better because of all the ways we are able to consume data?
Jamstack And Static Sites
Jamstack means publishing static sites. It’s the opposite of a pull architecture, where each request means fresh content from the database, instead, we push out all our content at once, pre-rendered, in static files, ready to be served.
This comes with a ton of benefits. Jamstack sites are easy to deploy. All your web server needs to be able to do is serve static files. Web servers are really good at serving static sites! Security-wise, Jamstack pages are a fortress. You actively cut all ties to systems that require authentication or handle sensitive data. Web servers serve in read-only mode. Some setups from popular providers even create an immutable copy of your site. No possibility to change anything on this disk.
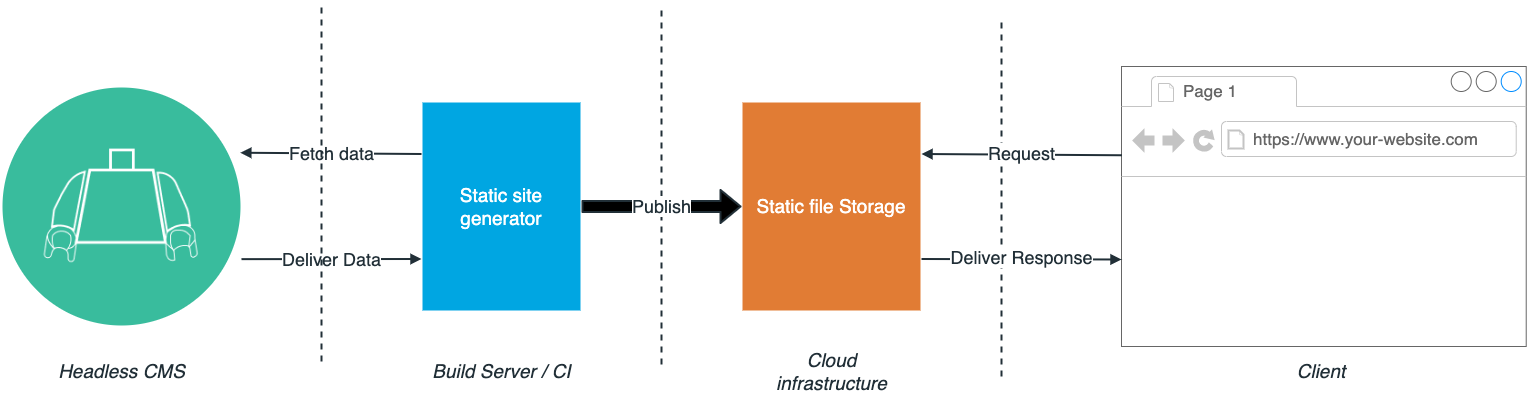
All you need is a static site generator, and if you want to scale, a build server. Services like Netlify and Vercel build static sites for you. Content updates happen at build time. The static site generator pulls the entire necessary content from a headless CMS once.
See this example with Storyblok and Next.js:
import { useStoryblokApi, StoryblokComponent,
} from '@storyblok/react'; export default function Home({ story }) { // Let's show what we got. return <StoryblokComponent blok={story.content} />;
} export async function getStaticProps({ preview = false }) { // Here, we are loading all data for static generation. const storyblokApi = useStoryblokApi(); let { data } = await storyblokApi.get(`cdn/stories/react`, { version: 'draft', }); return { props: { story: data ? data.story : false, preview, }, };
}Once the website is done building, all ties are cut. Your website runs without any connection to a content management system. From an operations point of view, this is fantastic. Not only did we introduce an error boundary and reduced channels to other systems, but we also cut off communication entirely because we don’t need it anymore.
Updates to your content require a rebuild. A CMS like Storyblok offers you to call a webhook once the publish button has been pressed. Thankfully, hosts like Vercel offer to create webhooks that rebuild your site.

It’s not all hunky-dory, though. While Jamstack sites have undeniable benefits, they also come with some problems. The bigger your site is, the slower your builds can be. If you have to have mission-critical updates, and some companies do, it might be unacceptable to wait a couple of minutes until you see an update. Heck, I’ve seen projects taking up to 30 minutes to publish new content. This is way too long if you need to react quickly.
Deployment Free Updates
If we think back to how monolithic content management systems dealt with retrieving content, we see that there was just one spot where the content was actually queried. Thanks to a headless CMS that gives you APIs to fetch data, we can now fetch content from multiple places.
We can use this to maneuver around some limitations we get when using Jamstack when we need to wait for a build to get an update. We can see the deployed static files as a robust, available baseline to serve our content from. For critical parts of our website, where real-time updates are of essence, we fetch data dynamically from our CMS.
This can be parts of your website, but also the entire content of an entire page. The following example shows how this can be done using Storyblok and Next.js:
import { useStoryblok, useStoryblokApi, StoryblokComponent,
} from '@storyblok/react'; export default function Home({ story: initialStory }) { // We are fetching new data from our CMS. let story = useStoryblok("react", { version: "draft" }); // If data isn't available, yet, we show the original static data. if (!story.content) { story = initialStory; } return <StoryblokComponent blok={story.content} />;
} export async function getStaticProps({ preview = false }) { // Here, we are loading all data for static generation. const storyblokApi = useStoryblokApi(); let { data } = await storyblokApi.get(`cdn/stories/react`, { version: 'draft', }); return { props: { story: data ? data.story : false, preview, }, };
}Next.js ergonomic APIs allow us to pinpoint the exact locations where we want to have data dynamically with a static fallback. And we increase our data accessing points.
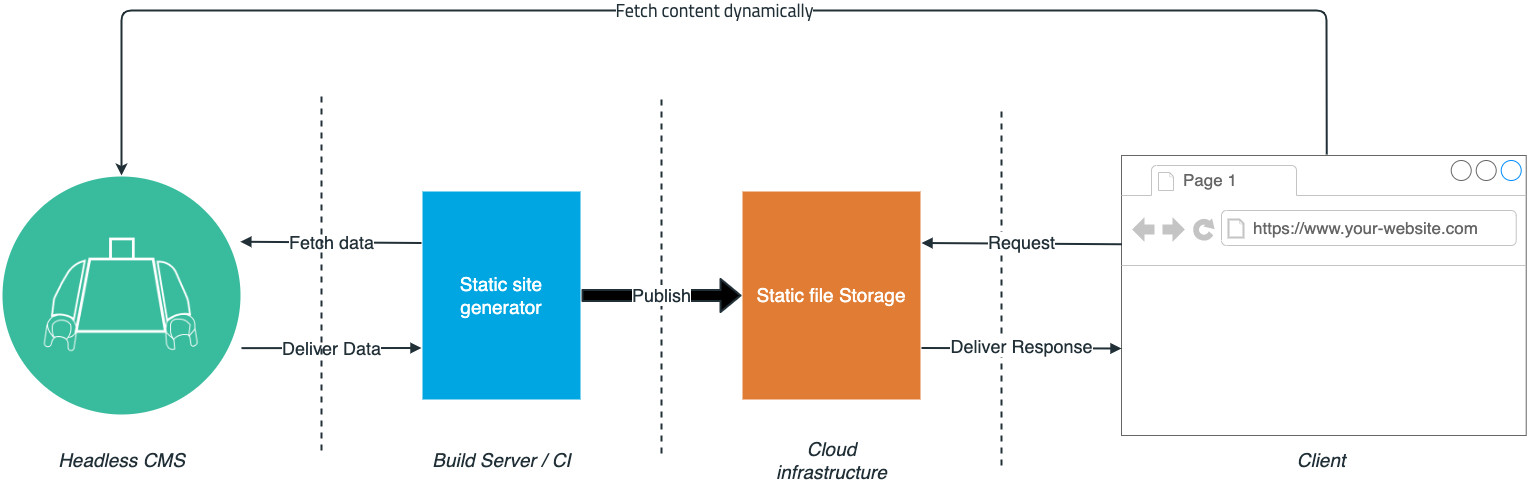
Press releases, news articles, and everything that needs to be published within a certain time frame can be done dynamically on the client-side — without losing the benefits of static site generation. You still can redeploy your website, but publishing at an exact point in time becomes an afterthought. Let the build run as long as it needs.
Not only do you get fast updates. If the connection to your CMS breaks for whatever reason, users are still able to see the old content. There’s no arguing that this is definitely better than seeing no content at all.
There are many more use cases for a model like this. Updates on time-critical pages are one thing but think of different modes for your site. You publish statically generated pages fetching all recent data at once at build time. You have a preview mode for your content creators and editors to see what they’re currently working on hosted someplace else.
import { useStoryblok, useStoryblokApi, StoryblokComponent,
} from '@storyblok/react'; export default function Home({ story: initialStory, preview }) { if (preview) { // Load draft articles in preview mode. let story = useStoryblok("react", { version: "draft" }); return <StoryblokComponent blok={story.content} />; } return <StoryblokComponent blok={initialStory.content} />;
} export async function getStaticProps({ preview = false }) { // Load published data in build mode. const storyblokApi = useStoryblokApi(); let { data } = await storyblokApi.get(`cdn/stories/react`, { version: 'published', }); return { props: { story: data ? data.story : false, preview, }, };
}Nice! Give your editors some taste of what they’re actually working on!
Incremental Static Updates
Fetching time-sensitive data on the client-side is one idea to update your page without a full rebuild. It’s great if you want to have fast updates, but you might see a huge switch between the pre-built. If your hosting solution allows it, tools like Next.js allow you to incrementally update content after a certain retention period.
This article on Smashing Magazine by Lee Robinson goes into incremental static regeneration in full detail. The story in a nutshell: The web server serves statically generated content. You define how long this content is supposed to be valid. If at the time of serving this period has elapsed, Next.js triggers a serverless function that renders the desired page new and overwrites the original page with the newly generated HTML. Quite a task, for you it’s just one line of code you need to add.
import { useStoryblok, useStoryblokApi, StoryblokComponent,
} from '@storyblok/react'; export default function Home({ story: initialStory }) { // We are fetching new data from our CMS. let story = useStoryblok("react", { version: "draft" }); // If data isn't available, yet, we show the original static data. if (!story.content) { story = initialStory; } return <StoryblokComponent blok={story.content} />;
} export async function getStaticProps({ preview = false }) { // Here, we are loading all data for static generation. const storyblokApi = useStoryblokApi(); let { data } = await storyblokApi.get(`cdn/stories/react`, { version: 'draft', }); return { props: { story: data ? data.story : false, preview, }, revalidate: 3600 // Check back after 1 hour if there's new content. };
}Now we have three points where we access our headless CMS from:
- Once a build for all available content.
- For time-sensitive data on the client-side. Fallback to the original content.
- In a serverless function for every page we want to update incrementally.

Soft Coupling
All three connection points work for different time frames.
- Real-time client-side data fetching has the shortest life span and gives you the most recent content.
- Incrementally generated static pages have a longer life span and give you content that is of a certain age.
- Build-time generated static pages have the longest life span and are as recent as you configure them. Their life span is significantly shorter if you rebuild on every content update, it’s longer if you only rebuild at code changes.

But by adding all the connection points to our CMS, something else has changed. We coupled ourselves more often to an external system than before, but every connection is allowed to fail.
If a real-time update on the client-side fails for whatever reason, we still see the content of the incrementally generated page. If this connection didn’t work, we see what we generated on build time.
Note: The examples above use Next.js mostly because Next.js allows us to get all that benefit with very little to do for us developers. Especially with the hooks from Storyblok data fetching becomes a single line of code. The same principles of soft coupling can be applied to other sites and frameworks as well.
Let’s say you generate all your content on the server-side using Express.js. The following route would fetch content with every request to the server:
app.get('/*', function (req, res) { var path = url.parse(req.url).pathname; console.log(path); path = path == '/' ? 'home' : path; Storyblok.get(`cdn/stories${path}`, { version: 'draft', }) .then((response) => { // Render content to HTML. res.render({ story: response.data.story, }); }) .catch((error) => { res.send(error); });
});If the bridge to our CMS fails, so does delivering our content. Adding another connection point serves cached content first and does updates in the background.
app.get('/*', function (req, res) { var path = url.parse(req.url).pathname; console.log(path); path = path == '/' ? 'home' : path; // Loading the cached content. let content = contentMap.get(path); if (content) { Storyblok.get(`cdn/stories${path}`, { version: 'draft', }).then((response) => { // Update in the background. contentMap.set(path, response); }); return res.send(content); } // Fetching the real content. Storyblok.get(`cdn/stories${path}`, { version: 'draft', }) .then((response) => { contentMap.set(path, response); res.send({ story: response.data.story, }); }) .catch((error) => { res.send(error); });
});And with some added metadata on revalidation, we can even check for updates after a certain period of time:
app.get('/*', function (req, res) { var path = url.parse(req.url).pathname; console.log(path); path = path == '/' ? 'home' : path; // Loading the cached content. let content = contentMap.get(path); if (content) { // Check if the revalidation window has elapsed. if (content.fetchedDate + content.revalidate < Date.now()) Storyblok.get(`cdn/stories${path}`, { version: 'draft', }).then((response) => { contentMap.set(path, { response, fetchedDate: content.fetchedDate, revalidate: content.revalidate, }); }); return res.send(content.response); } // Fetching the real content. Storyblok.get(`cdn/stories${path}`, { version: 'draft', }) .then((response) => { // Store with some metadata for revalidation. contentMap.set(path, { response, fetchedDate: Date.now(), revalidate: 3600000, //in ms }); res.send({ story: response.data.story, }); }) .catch((error) => { res.send(error); });
});Add this with some client-side caching using stale-while-revalidate to add an extra fallback for your revisiting users.
Bottom Line
Headless content management systems allow you to add a clear boundary between the content you deliver and the content that is being maintained by others. This clear separation lets a CMS focus on content management again, instead of blurring the line between content and its design.
But it’s not only that. When deploying websites, there’s rarely a one-size-fits-all solution. Some websites benefit from server-rendered pages, some prefer statically generating content upfront. A headless CMS works with all approaches, allowing you to mix and match depending on your needs.
We just played through one possibility of adding a headless CMS to our stack and connecting it from various sources to make our site more resilient without losing the flexibility to deliver time-relevant content. And that’s just one of many.
(vf, yk, il)